
JPA 즉시로딩과 지연로딩
즉시로딩: Entity를 불러올때 연관된 Entity를 즉시 fetch해서 함께 불러온다.
지연로딩: 연관된 Entity가 필요할때 fetch해서 불러온다.
//default 로딩 전략은 FetchType.EAGER
@ManyToOne(fetch = FetchType.LAZY)
@OneToOne(fetch = FetchType.LAZY)
Entity 1개 조회할때
@Test
@Transactional
void findOne() {
//fetchType이 EAGER일때: findOne을 호출하면 team도 함께 1차 캐시에 올라온다. -> query 총 1번
//fetchType이 LAZY일때:
//findOne을 호출하면 user를 가져오기 위한 query 1번이 실행되고 fetchType이 Lazy이기 때문에, team은 1차 캐시에 올라오지 않은 상태.
//따라서, team을 호출하면 team을 1차 캐시로 가져오기 위한 query가 1번 더 실행된다. -> query 총 2번
User user = userService.findOne(1L);
Team team = user.getTeam();
team.getName();
}
여러개의 Entity를 조회할때 → 1+N 문제 발생
@Test
@Transactional
void findAll() {
//fetchType이 EAGER일때: EAGER로 설정되어있기 때문에 findAll()시에 모든 user를 찾는 query 1번과 team을 불러오는 query 10번이 추가로 실행된다. -> query 총 11번
//fetchType이 LAZY일때: EAGER와 같이 N+1 문제가 발생한다. 하지만, EAGER는 user를 가져올때 이미 문제가 발생하지만 LAZY는 이후 team을 호출할때 query가 발생하게 된다. -> query 총 11번
List<User> users = userService.findAll();
for (User user : users) {
Team team = user.getTeam();
//EAGER는 연관 Entity를 따로 호출하지 않아도 1+N 번 쿼리 발생
team.getName();
}
}
[ N : 1 ] 관계에서 1+N 문제 해결 - fetch join 사용
N:1 관계에서 1+N 문제를 해결하기 위해서는 fetch join을 사용할 수 있다. N:1 관계에서 1에 해당하는 Entity를 join해서 하나의 테이블로 만들면 결과 테이블의 row 갯수에 변화가 없고 query는 1+N이 아니라 1번 요청된다.
//User.java 연관관계 설정
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
@OneToMany(mappedBy = "user")
private final List<Todo> todos = new ArrayList<>();//Repository 코드
@Query("select u from User u join fetch u.team")
List<User> findAllWithTeam();
//Test 코드
@Test
@Transactional
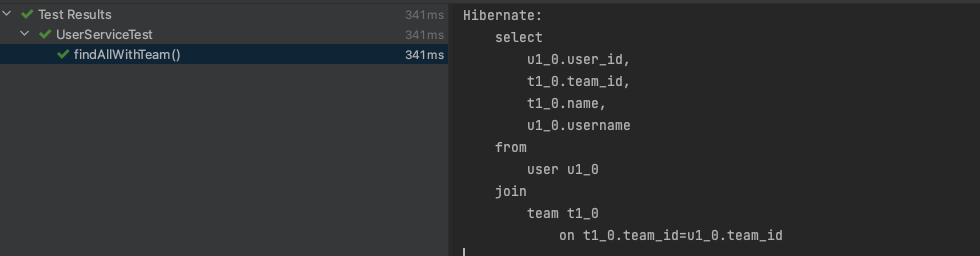
void findAllWithTeam() {
List<User> users = userService.findAllWithUser();
for (User user : users) {
Team team = user.getTeam();
//fetch join이 없는 경우와 달리 연관 Entity인 Team을 users.size()만큼 조회해도
//쿼리가 1번만 나가는것을 볼 수 있다.
team.getName();
}
}
[ 1 : N ] 관계에서 1+N 문제 해결 - 컬렉션 fetch join
1 : N 관계에서도 마찬가지로 fetch join을 이용해 1+N 문제를 해결한다. 아래와 같이 1:N 관계에서도 fetch join을 이용해 1+N 문제를 해결할 수 있다.
//Repository 코드
@Query("select u from User u join fetch u.team t join fetch u.todos ts")
List<User> findAllWithTeamAndTodos();
//Test 코드
@Test
@Transactional
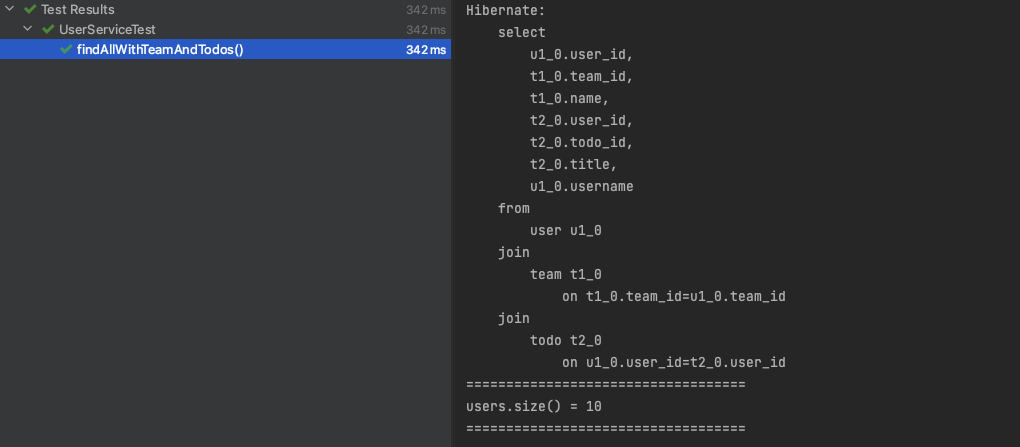
void findAllWithTeamAndTodos() {
List<User> users = userService.findAllWithUserAndTodos();
for (User user : users) {
Team team = user.getTeam();
team.getName();
List<Todo> todos = user.getTodos();
for (Todo todo : todos) {
todo.getTitle();
}
}
System.out.println("===================================");
System.out.println("users.size() = " + users.size());
System.out.println("===================================");
}
1:N 관계에서도 fetch join을 이용해 1+N 문제를 잘 해결하지만, 한가지 문제점이 있다. 위 코드의 결과를 보면 users 리스트의 크기가 10으로 출력되는데 hibernate가 날린 쿼리를 그대로 DB에서 실행해보면 아래와 같다. user별로 todo를 10개씩 생성해놨는데 jpa는 10개의 데이터를 반환하는 반면 DB에서는 100개의 데이터를 반환한다.
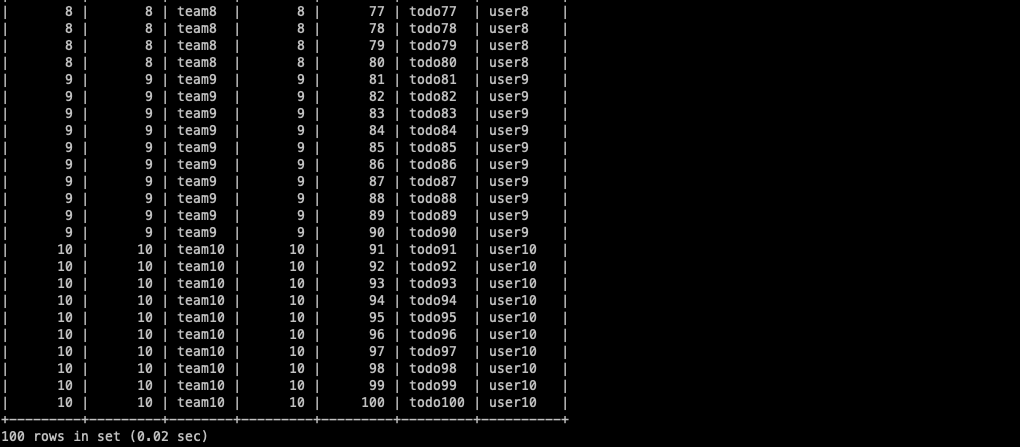
user 데이터가 10개, user별로 todo 데이터가 10개씩 있으니 총 100개의 데이터가 반환된 것이다. JPA는 조회 기준 Entity로 결과값을 최적화해 이 문제를 자동으로 처리해주지만, DB에서는 그렇지 못하다. (알아본 내용으로는 JPA에서도 JPQL에 distinct 키워드를 넣어줘야 1:N 연관 데이터를 중복처리 해줬는데 지금은 자동으로 되나보다. 당연히 DB에서는 모든 column의 데이터가 같아야하기 때문에 중복처리를 못해준다.) 따라서, 1:N관계에서의 fetch join은 DB에 과부하를 줄 수 있으니 최대 1개만 사용하도록 권장한다. 유의해서 사용하자!
[ 1 : N ] 관계에서 fetch join 페이징
결론부터 말하자면, 1:N 관계에서 페이징이 포함된 조회를 할때 fetch join은 쓰지 않는 것이 좋다. N:1 관계의 Entity를 먼저 fetch join으로 페이징처리해 불러오고 1:N관계의 Entity는 @BatchSize 또는 default_batch_fetch_size 옵션을 이용해 select-in 절로 별도로 불러오는 것이 좋다.
위 DB 데이터를 기준으로, 페이징을 할때 offset, limit을 주는데 query에 1:N 연관관계 Entity를 fetch join 하게되면 DB는 100개의 데이터가 있는 테이블에서 offset, limit을 설정해 값을 반환하게된다.
JPA는 이를 막기 위해서 DB에 쿼리를 날릴때 offset, limit 값을 전달하지 않고, 100개의 데이터를 메모리에 올린 후 자체적으로 페이징을 진행하게된다. 만약 결과 테이블의 크기가 100만개라면 100만개의 데이터가 메모리에 올라가게될 것이다. 따라서, 쿼리는 한 번 나가지만 JPA는 아래와 같이 경고문을 남긴다.
//Repository 코드
public List<User> findAllWithTeamAndTodos_paging(int offset, int limit) {
return em.createQuery("select u from User u join fetch u.team t join fetch u.todos ts", User.class)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
//Controlelr 코드
@GetMapping("/v4")
public void findAllWithTeamAndTodos_paging() {
List<User> users = userService.findAllWithTeamAndTodos_paging(0, 5);
for (User user : users) {
System.out.println("user.getUsername() = " + user.getUsername());
}
}
2024-01-12T18:03:39.586+09:00 WARN 32522 --- [nio-8080-exec-3]
org.hibernate.orm.query : HHH90003004:
firstResult/maxResults specified with collection fetch; applying in memory
1:N 관계에서 컬렉션 fetch join과 페이징을 함께 사용할때, 1+N 문제를 해결하는 방법은 통상 두가지 절차를 따르면 된다.
- 추가 쿼리를 허용
- N:1 관계의 Entity를 먼저 fetch join하고 반환받은 결과 리스트에서 1:N 관계의 Entity 데이터를 가져온다.
- 그럼 1+N 문제가 발생한다고 생각할 수 있지만, 그 문제를 아래 `default_batch_fetch_size`가 해결해준다.
- default_batch_fetch_size 설정
- default_batch_fetch_size를 설정하면 JPA는 설정한 size만큼씩 in 쿼리를 날려 데이터를 한번에 당겨온다. 따라서, limit이 10이고 default_batch_fetch_size가 10일때 in 쿼리에 10개의 데이터를 포함시켜 1번의 쿼리로 1:N 관계의 데이터를 가져오는 것이다. limit이 12이고 default_batch_fetch_size가 10이라면 2개의 쿼리가 전달될 것이다. (한 번에default_batch_fetch_size 만큼씩 반복)
위 두가지 절차를 따르고 default_batch_fetch_size를 적절하게 설정한다면 1:N 페이징 컬렉션 fetch join도 1+N이 아닌 1+1 번의 쿼리로 데이터를 가져올 수 있다.
select-in 절을 사용할때 QueryPlanCache를 주의하자
JPA hibernate Query Plan Cache로 인한 OutOfMemory 해결
OOM 에러 주겨버리기ㅣㅣㅣ
velog.io
위에서 페이징 컬렉션 fetch join을 할때 default_batch_fetch_size 를 사용해 size만큼 select-in 절로 결과값을 받아와 1+N 문제를 해결했다. 일반적으로 사용하는 JPA 구현체 Hibernate는 select-in이 포함된 쿼리를 날릴때 QueryPlanCache를 주의해야하는데, 잘못하면 out-of-memory가 발생할 수 있다.
Hibernate는 모든 JPQL 쿼리를 AST(Abstract Syntax Tree)로 변환해 SQL을 생성하는데 이 과정에서 소모되는 비용을 줄이고자 분석된 쿼리를 저장하는 QueryPlanCache 를 제공한다. Hibernate는 쿼리를 실행하기 전에 QueryPlanCache 를 먼저 확인하고 사용가능한 쿼리가 있는 경우에 SQL을 가져와 사용하고, 없는 경우에는 QueryPlanCache에 저장하게된다.
Hibernate Query Plan Cache | Baeldung
Have a look at how Hibernate's Query Plan Cache can help improve the performance of an application.
www.baeldung.com
QueryPlanCache 를 주의해야하는 이유는 바로 select-in 절에서 in으로 넘겨주는 parameter의 갯수가 서로다르다면 다른 select-in쿼리로 간주해 QueryPlanCache에 개별적으로 저장한다는 것이다. 예를 들어, default_batch_fetch_size 를 500으로 설정하고 서비스를 운영하는데 지속적으로 쿼리를 날리다보니 in 절의 사이즈가 500개의 다른 쿼리가 모두 날아갔다고 할때, QueryPlanCache 에는 같은 쿼리이지만 in으로 넘겨주는 parameter의 갯수만 다른 쿼리가 500개가 쌓일 것이다.
공식 문서에 따르면 QueryPlanCache 의 default size는 2048MB인데 어플리케이션의 메모리 용량이 그 이하라면, QueryPlanCache가 계속 쌓이다가 어플리케이션은 out-of-memory를 발생시킬 것이다. 이러한 문제를 해결하는 방법은 in-clause-parameter-padding 옵션을 이용하는 것이다. in-clause-parameter-padding 은 select-in 절의 in 파라미터 갯수를 제한하는 것인데, 2의 제곱 단위로 묶어서(Padding) 쿼리를 날리는 방식이다.
예를 들어 아래와 같이 파라미터 사이즈가 서로 다른 4개의 select-in 쿼리를 보낸다고 할때, QueryPlanCache에는 4개의 쿼리가 쌓일 것이다.
select *
from User u
where u.id in (1,2,3)
//...
where u.id in (1,2,3,4)
//...
where u.id in (1,2,3,4,5)
//...
where u.id in (1,2,3,4,5,6)
하지만,in-cluase-parameter-padding 옵션을 사용할 경우에는 Hibernate에서 위 쿼리를 2의 제곱 단위로 묶어 아래와 같이 변경해서 날리게 된다.
spring.jpa.properties.hibernate.query.in_clause_parameter_padding=trueselect *
from User u
where u.id in (1,2,3,3)
//...
where u.id in (1,2,3,4)
//...
where u.id in (1,2,3,4,5,5,5,5)
//...
where u.id in (1,2,3,4,5,6,6,6)
이렇 in-clause-parameter-padding 옵션을 사용하게되면 서로 다른 in 쿼리를 날려도 QueryPlanCache 메모리 사용량에 부담이 없고 코드의 변경 없이 성능을 향상시키는 좋은 방법이라고 한다.